背景
某日午休醒来,睡意朦胧之际告警群嗡嗡作响,查看记录心中默叹:优惠券中心这帮人今天没烧香啊,上个线搞出问题来了。
接杯热水开始下午工作吧,没多久收到反馈:间歇性页面响应慢,心中一阵纳闷,我这业务近期也没改动,优惠券这种边角业务,怎么就影响到我了,赶紧排查。
若干分钟后,核心业务开始受影响,RT变大,QPS下降明显,众架构师齐上阵,排查问题迅速解决,业务恢复正常。
分析
翻看日志、分析监控大致还原了当时的现场。
- 核心服务A的某个接口A-1对非核心服务B有部分依赖;
- 服务B部署失败,导致只有少量实例正常运行;
- 随着业务的进行服务B无法及时处理,出现堆积;
- 接口A-1阻塞等待,出现堆积;
- 接口A-1耗尽服务A的线程池;
- 服务A因无空余线程,全部阻塞;
这种现象统称为:雪崩效应
雪崩效应
是一种因服务提供者的不可用导致服务调用者的不可用,并将不可用逐渐放大的过程
雪崩图解
1.当服务都健康的时候如下图所示
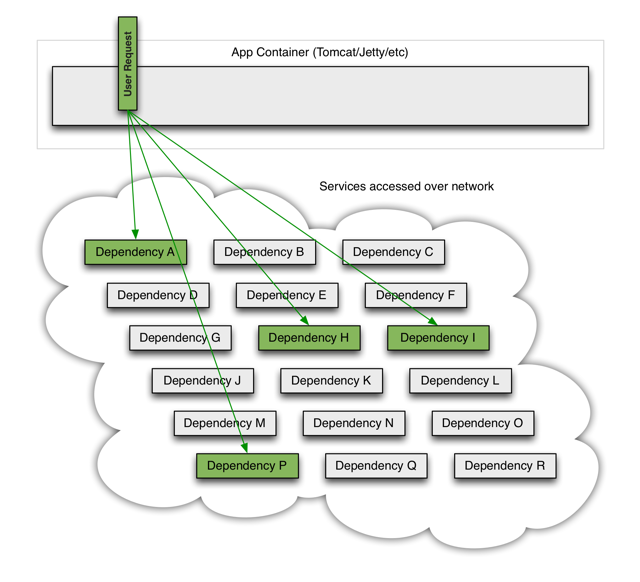
2.当其中一个服务出现延迟,将会阻塞整个用户的请求
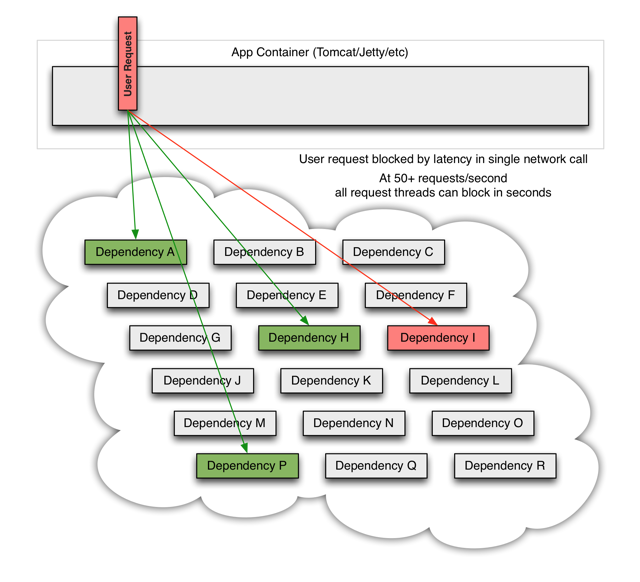
3.一个服务的延迟会导致单位时间内资源一直被占用,应用的其它请求进来也会延迟,紧接着队列开始堆积,线程还有其他系统资源不释放,甚至引发整个系统的级联失败,出现雪崩。
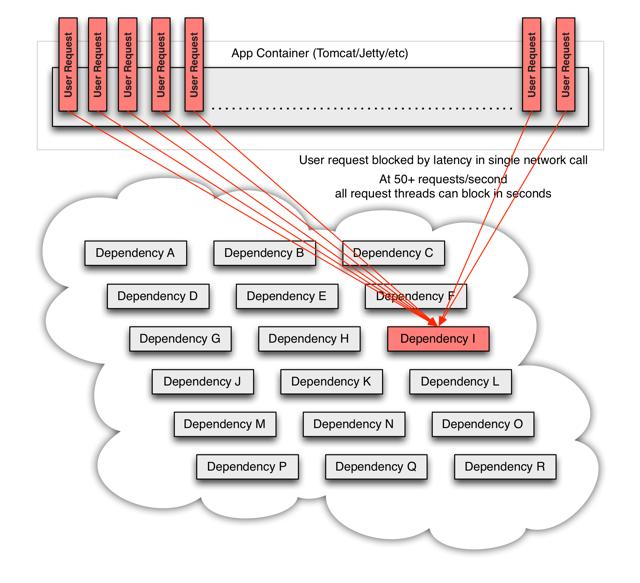
雪崩形成原因
1)服务提供者不可用
a)硬件故障:硬件损坏造成的服务器主机宕机, 网络硬件故障造成的服务提供者的不可访问
b)程序Bug:
c) 缓存击穿:缓存击穿一般发生在缓存应用重启, 所有缓存被清空时,以及短时间内大量缓存失效时. 大量的缓存不命中, 使请求直击后端,造成服务提供者超负荷运行,引起服务不可用
d)用户大量请求:在秒杀和大促开始前,如果准备不充分,用户发起大量请求也会造成服务提供者的不可用
2)重试加大流量
a)用户重试:在服务提供者不可用后, 用户由于忍受不了界面上长时间的等待,而不断刷新页面甚至提交表单
b)代码逻辑重试: 服务调用端的会存在大量服务异常后的重试逻辑
3)服务调用者不可用
a)同步等待造成的资源耗尽:当服务调用者使用同步调用 时, 会产生大量的等待线程占用系统资源. 一旦线程资源被耗尽,服务调用者提供的服务也将处于不可用状态, 于是服务雪崩效应产生了。
解决办法
服务熔断
一般是指软件系统中,由于某些原因使得服务出现了过载现象,为防止造成整个系统故障,从而采用的一种保护措施,所以很多地方把熔断亦称为过载保护。很多时候刚开始可能只是系统出现了局部的、小规模的故障,然而由于种种原因,故障影响的范围越来越大,最终导致了全局性的后果。
服务降级
当服务器压力剧增的情况下,根据当前业务情况及流量对一些服务和页面有策略的降级,以此释放服务器资源以保证核心任务的正常运行。
业界方法:hystrix
hystrix是一个帮助解决分布式系统交互时超时处理和容错的类库, 它同样拥有保护系统的能力。
对外依赖包括第三方类库的依赖提供延迟和失败保护
阻断传递失败,防止雪崩
快速失败并即时恢复
合理的fallback和优雅降级
提供近实时的监控
Hystrix应对
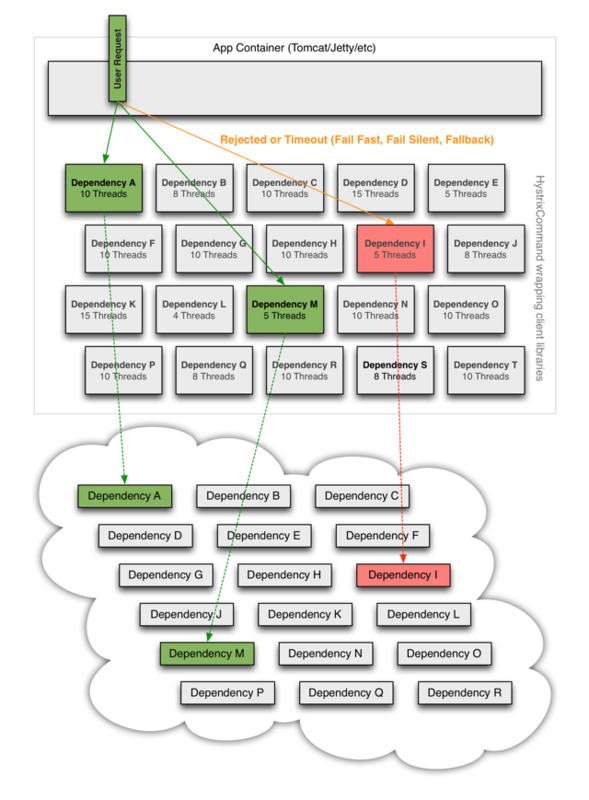
- hystrix把每个依赖都进行隔离,对依赖的调用全部包装成HystrixCommand或者HystrixObservableCommand
- 对依赖的调用耗时设置阀值,如果超过阀值直接判定超时
- 对每个依赖维护一个连接池,如果连接池满直接拒绝访问
- hystrix评估调用失败,调用超时,线程拒绝,调用成功的比例,如果超过指定的阀值直接走熔断处理,对依赖的访问直接走fallback逻辑(fallback逻辑使用者自己实现)
- 熔断生效后,会在设定的时间后放出一个请求来探测依赖是否恢复,依赖的应用恢复后关闭熔断
原理
1. 隔离:
Hystrix隔离方式采用线程/信号的方式,通过隔离限制依赖的并发量和阻塞扩散
1)线程隔离
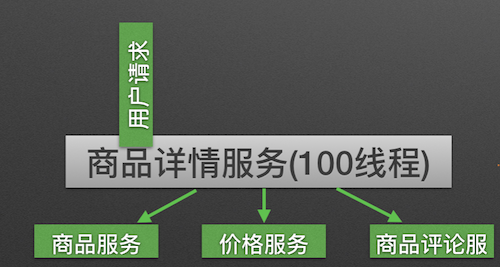
Hystrix在用户请求和服务之间加入了线程池。
Hystrix为每个依赖调用分配一个小的线程池,如果线程池已满调用将被立即拒绝,默认不采用排队.加速失败判定时间。线程数是可以被设定的。
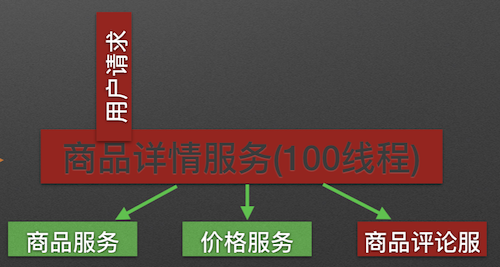
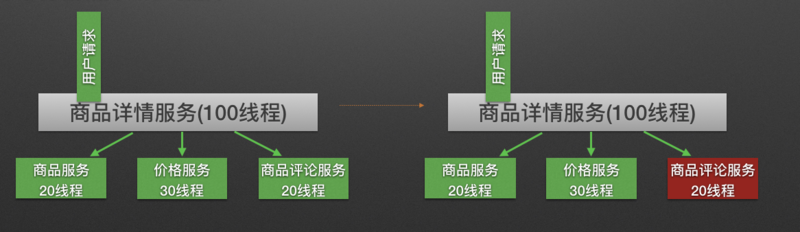
原理:用户的请求将不再直接访问服务,而是通过线程池中的空闲线程来访问服务,如果线程池已满,则会进行降级处理,用户的请求不会被阻塞,至少可以看到一个执行结果(例如返回友好的提示信息),而不是无休止的等待或者看到系统崩溃。
隔离前
问题时
隔离后
2)信号隔离
信号隔离也可以用于限制并发访问,防止阻塞扩散, 与线程隔离最大不同在于执行依赖代码的线程依然是请求线程(该线程需要通过信号申请, 如果客户端是可信的且可以快速返回,可以使用信号隔离替换线程隔离,降低开销。信号量的大小可以动态调整, 线程池大小不可以。
2. 熔断:
如果某个目标服务调用慢或者有大量超时,此时,熔断该服务的调用,对于后续调用请求,不在继续调用目标服务,直接返回,快速释放资源。如果目标服务情况好转则恢复调用。
熔断器:Circuit Breaker
熔断器是位于线程池之前的组件。用户请求某一服务之后,Hystrix会先经过熔断器,此时如果熔断器的状态是打开(跳起),则说明已经熔断,这时将直接进行降级处理,不会继续将请求发到线程池。熔断器相当于在线程池之前的一层屏障。每个熔断器默认维护10个bucket ,每秒创建一个bucket ,每个blucket记录成功,失败,超时,拒绝的次数。当有新的bucket被创建时,最旧的bucket会被抛弃。
-
Closed:熔断器关闭状态,调用失败次数积累,到了阈值(或一定比例)则启动熔断机制;
-
Open:熔断器打开状态,此时对下游的调用都内部直接返回错误,不走网络,但设计了一个时钟选项,默认的时钟达到了一定时间(这个时间一般设置成平均故障处理时间,也就是MTTR),到了这个时间,进入半熔断状态;
-
Half-Open:半熔断状态,允许定量的服务请求,如果调用都成功(或一定比例)则认为恢复了,关闭熔断器,否则认为还没好,又回到熔断器打开状态;
测试
众架构师集成了hystrix后就提测了,作为测试做了简单梳理
测试期望:
- 当业务受阻时,业务响应时间会变大
- 当触发熔断时,会极大地降低业务响应时间,返回预配置的fallback内容,熔断器处于open状态
- 当触发熔断后,单位间隔内会放行一小部分量,熔断器处于half-open状态
- 当触发熔断后,业务恢复时,会正常关闭熔断器,返回正常业务数据,熔断器处于closed状态
测试拆解
1.确定待测试的服务和测试内容
通过模拟阻塞、正常、由正常变阻塞、由阻塞变正常的环境,来确保熔断机制正常生效
2.配置hystrix相关参数;
-
circuitBreakerSleepWindowInMilliseconds = 5000; //如果熔断开关处于打开状态,且在一个时间窗口内,则允许一次访问进行测试
-
circuitBreakerErrorThresholdPercentage = 50;//如果当前采样的错误率小于阀值,则不进行熔断
-
circuitBreakerRequestVolumeThreshold = 20; //如果当前采样的总请求数小于阀值,则不进行熔断
-
and so on
3.设计测试方案
- 大力出奇迹:恒定线程压测consumer,大力压测service provider,待provider出现瓶颈后,观察consumer的各项指标
业务中做过大量优化设计,provider性能奇好无比,单台工作机没法压出性能瓶颈,又找不到空闲压力机,放弃
- 控制zk: 恒定线程压测consumer,通过手动启用、禁用zk中的provider,模拟阻塞状态,观察consumer的各项指标
zk关闭后主动通知consumer,导致触发业务中的异常兼容代码,模拟失败,放弃
- 控制服务器:恒定线程压测consumer,通过手动start、stop服务器中的provider,模拟阻塞状态,观察consumer的各项指标
服务开启、关闭主动上报zk,zk主动通知consumer,结果同上一方案,模拟失败,放弃
- 自己动手丰衣足食: 修改provider业务代码,增加条件模拟阻塞状态,观察consumer的各项指标
就它了!Let’s do it! 通过hard code强加sleep逻辑,模拟阻塞情况,每分钟前30秒阻塞,后30秒恢复,压测观察5分钟
/**
* @description 每一分钟的前30秒阻塞,后30秒放开
*/
@Override
public long getContent(long id) {
logger.info("测试熔断:start" + Thread.currentThread().getName());
Timestamp time = new Timestamp(new Date().getTime());
int currentSeconds = time.getSeconds();
try {
if (currentSeconds <= 30) {
Thread.sleep(hystrixSleepTime);
}
}catch (Exception e){
e.printStackTrace();
}
logger.info("测试:over" + Thread.currentThread().getName());
#业务代码
4.祭出jmeter测试压测之
测试结果
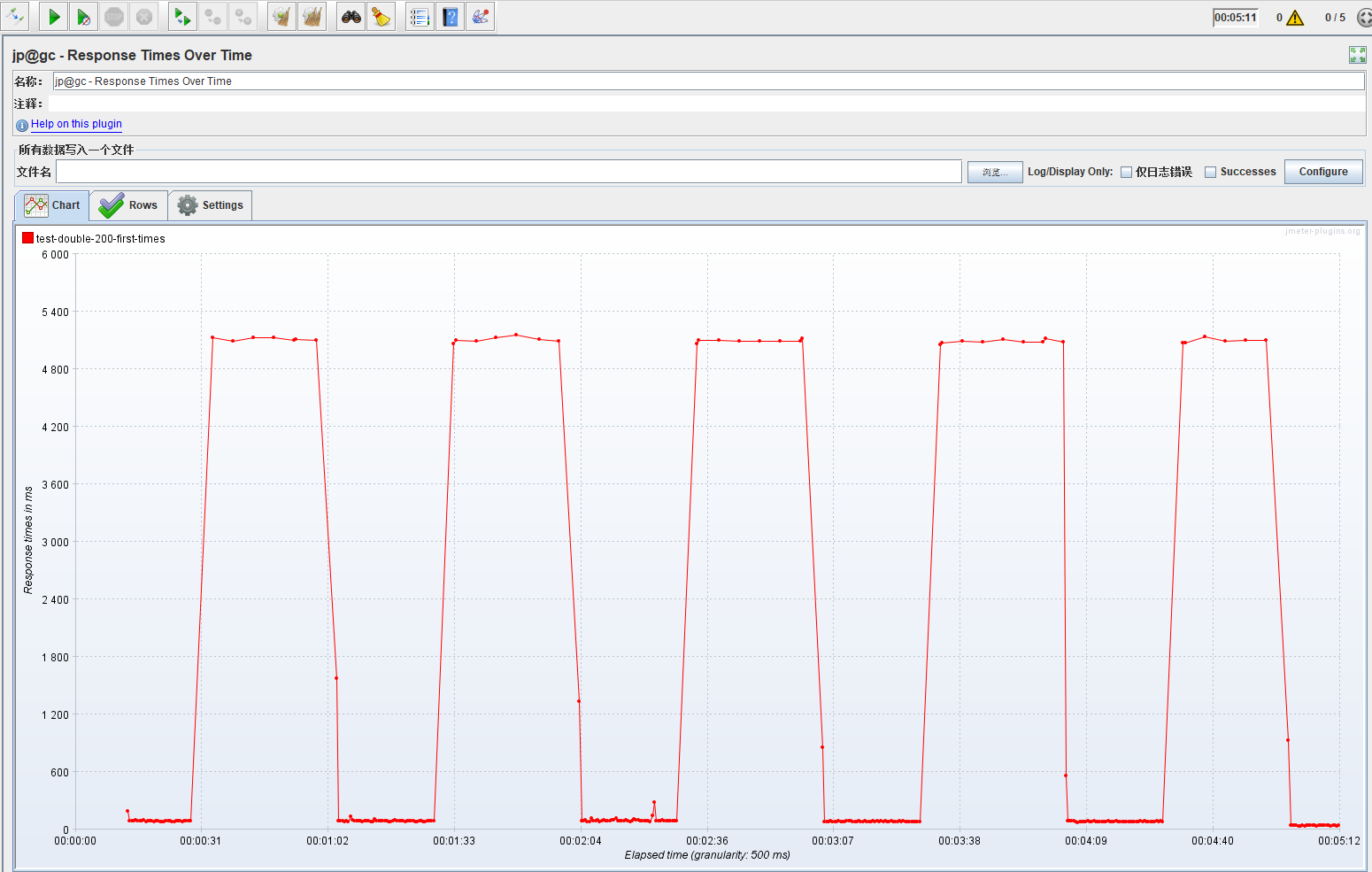
1.少量请求未触发熔断
采样频率小于设置阈值,未触发熔断,服务间隔性阻塞
2.适量请求延后触发熔断
开始阻塞后,响应时间变长
①当经过一段时间符合熔断条件时,触发熔断,响应时间大幅减少
②每隔熔断间隔段熔断器会处于半打开状态进行请求,响应时间小幅度上升
③当服务恢复后,熔断器关闭,响应时间略微产生波动
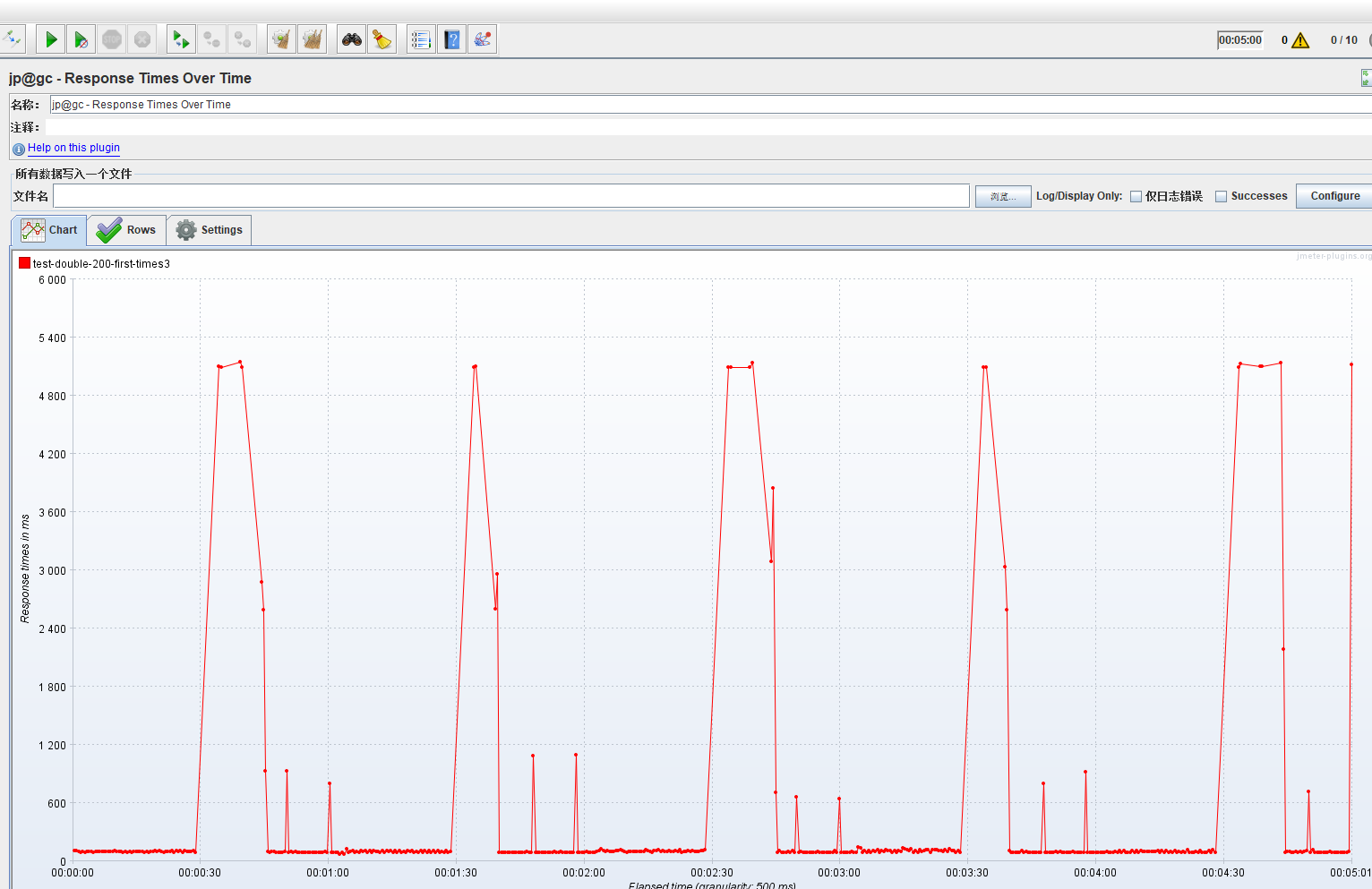
3.海量请求瞬间触发熔断
开始阻塞后,迅速触发熔断,响应时间立即减少
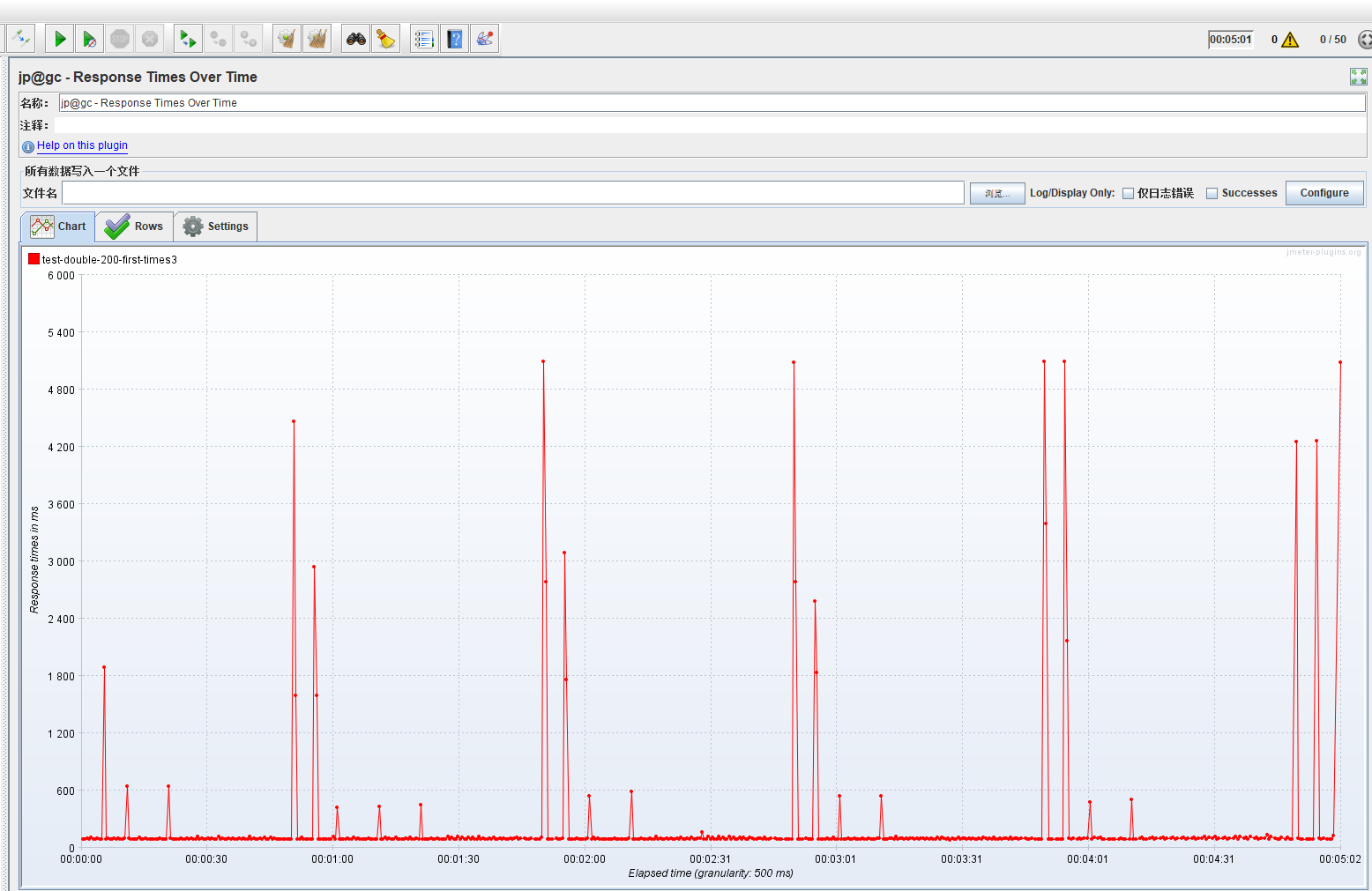 响应结果断言周期性pass与fail,结合上一张图表明:
熔断触发立即返回预设结果;
熔断关闭立即返回正常结果;
响应结果断言周期性pass与fail,结合上一张图表明:
熔断触发立即返回预设结果;
熔断关闭立即返回正常结果;
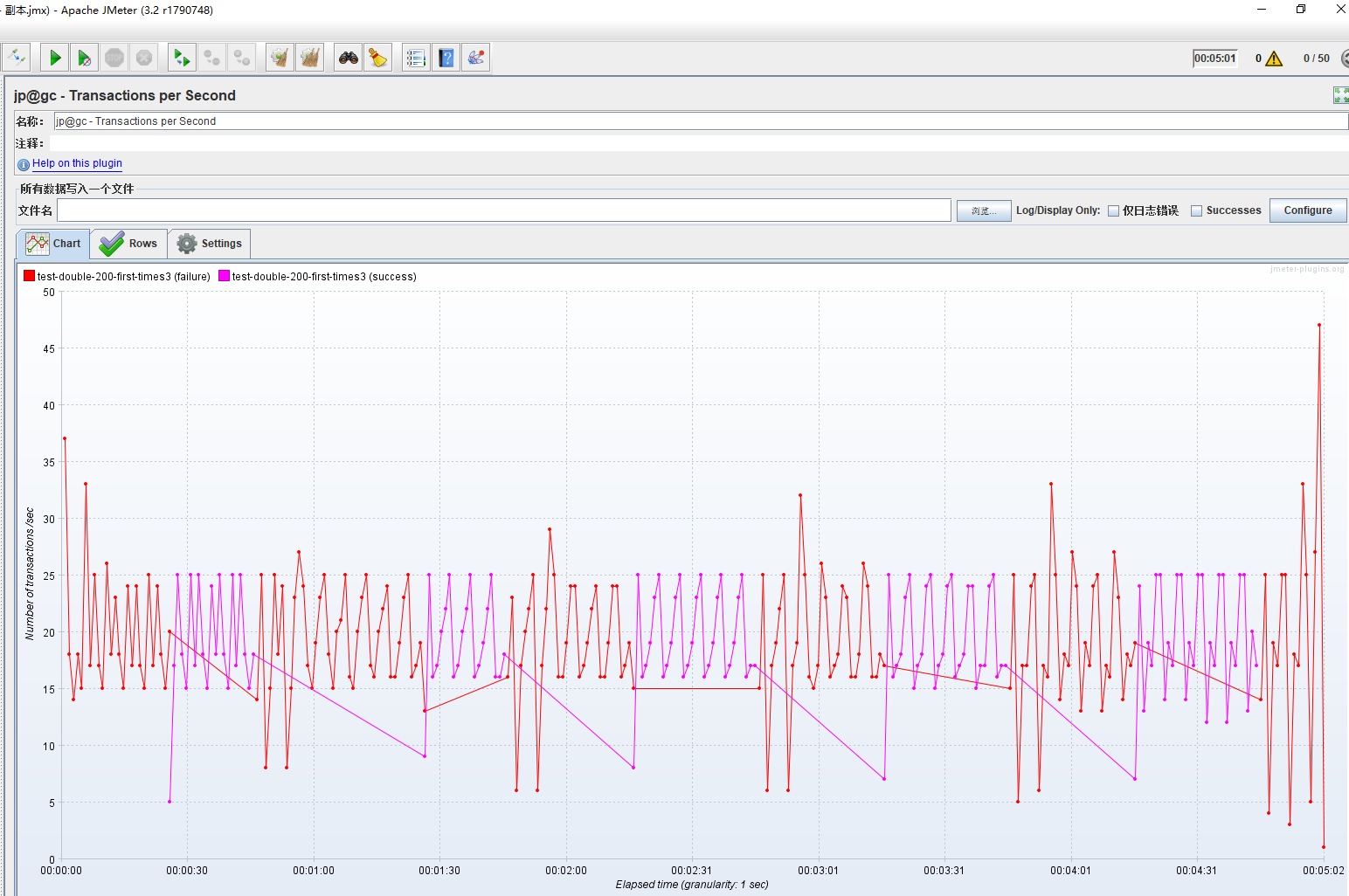
结论
基本符合预期
参考文章
Netflix 官方文档 https://github.com/Netflix/Hystrix/wiki
熔断机制HYSTRIX https://segmentfault.com/a/1190000012338949
服务熔断、降级、限流、异步RPC – HyStrix https://blog.csdn.net/chunlongyu/article/details/53259014